近期,我院工本口子库漫画视觉感知与机器学习团队在计算机视觉与多模态感知方向取得系列重要进展。
团队与南方科技大学、英国华威大学合作,在人工智能国际顶级会议IEEE/CVF International Conference on Computer Vision 2023 (ICCV2023)发表跨模态视频目标分割的最新研究成果。ICCV是由国际电子工程师协会计算机学会(IEEE Computer Society)和计算机视觉基金会(CVF)联合主办,每两年举办一次,是人工智能领域公认的计算机视觉三大顶会之一,是CCF- A类会议。我校为论文第一完成单位,工本口子库漫画硕士研究生李光辉为论文第一作者,刘恒教授为第一通讯作者。
当前深度学习参考视频目标分割(RVOS,Referring Video Object Segmentation)已有工作都要求特定场景具有足够丰富的文本及视频多模态联合标注数据。但在缺乏标注数据的新应用场景,以较低成本实现多样化视频有效目标分割是一个迫切需要解决的问题。团队基于Transformer架构,提出了一种跨模态少样本亲和力学习的新方法,根据少量样本建立多模态亲和关系,为多样化的数据学习新的语义信息;首次构建了的FS-RVOS(Few-shot RVOS)基准,在只有少量标注样本的情况下,采用交叉注意力方式分层融合视觉和文本特征以获得特定类别的鲁棒特征表示,为最终实现真实陌生场景参考视频目标分割指明了方向。
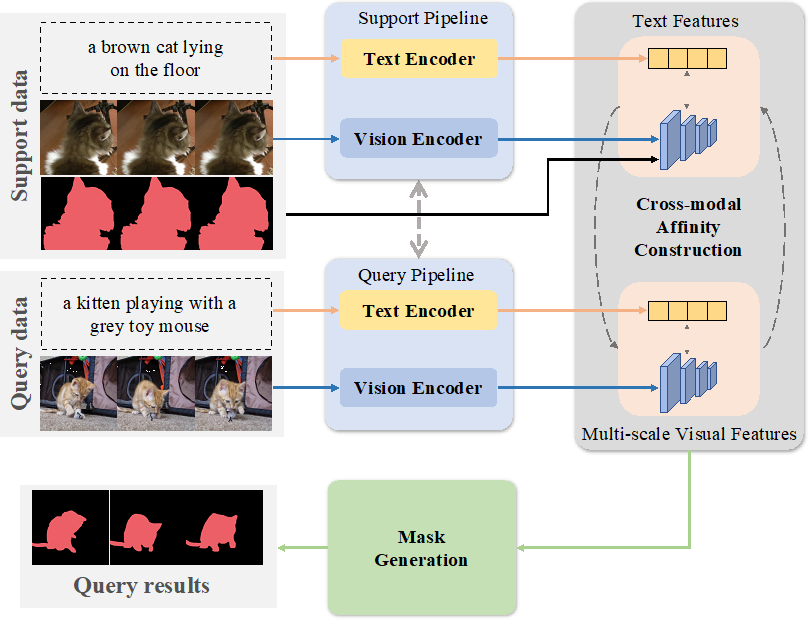
(跨模态少样本亲合力学习参考视频分割)
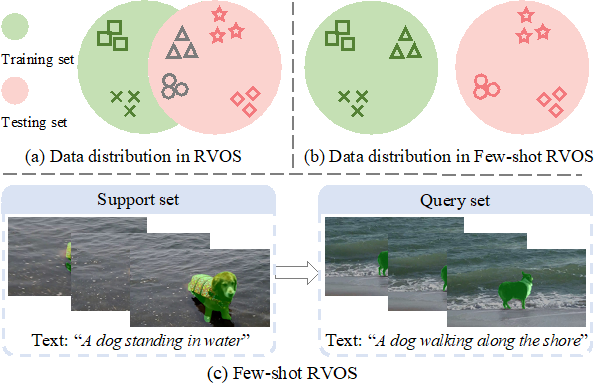
(FS-RVOS与RVOS的问题不同)
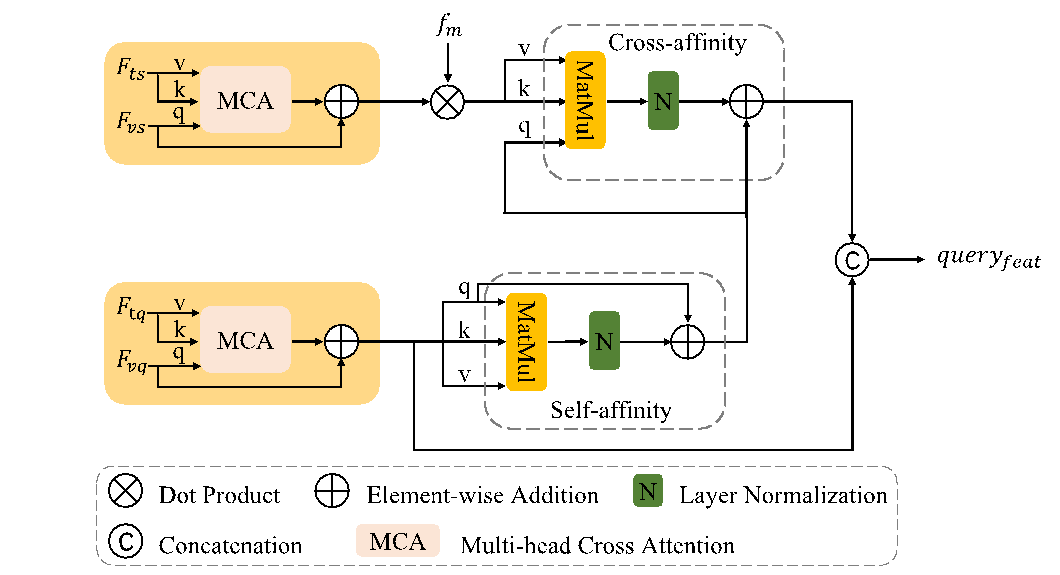
(跨模态亲和力(CMA)模块的架构)

(FS-RVOS基准数据示例)
对于超声临床诊断而言,超声影像超分辨(ultrasound image super-resolution)可以提高超声成像质量,从而提高疾病诊断的准确性。但由于传感设备和传输介质的差异,实际场景中超声成像其退化模糊过程是未知且不可控的。为了解决未知退化场景超声医学影像准确超分辨的难题,团队提出了一种有效的基于退化模糊自估计且结合渐进残差学习和记忆提升机制的超声影像盲超分方法,初步实现了真实场景超声影像准确超分辨。相关研究成果发表在人工智能、计算机医学信息交叉领域一区TOP期刊《IEEE Journal of Biomedical and Health Informatics》(IF: 7.7)。我校为论文第一完成单位,工本口子库漫画刘恒教授、硕士生刘建勇分别为论文第一、第二作者。
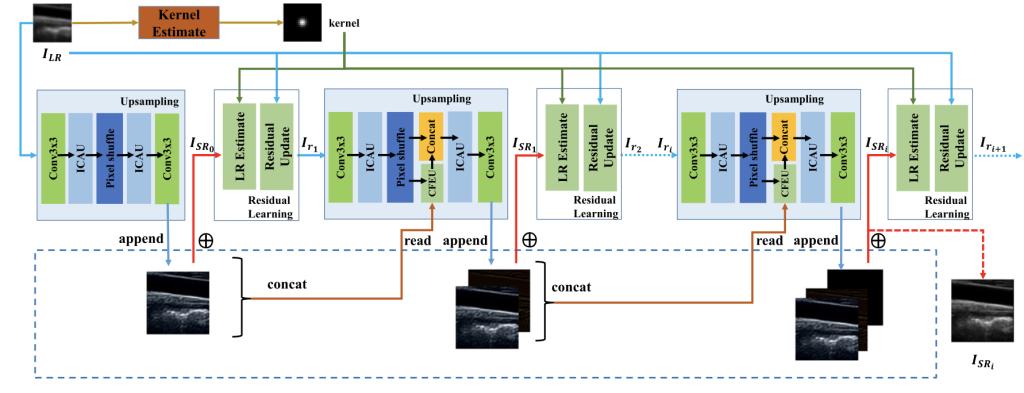
(渐进残差学习与记忆升级超声影像盲超分)
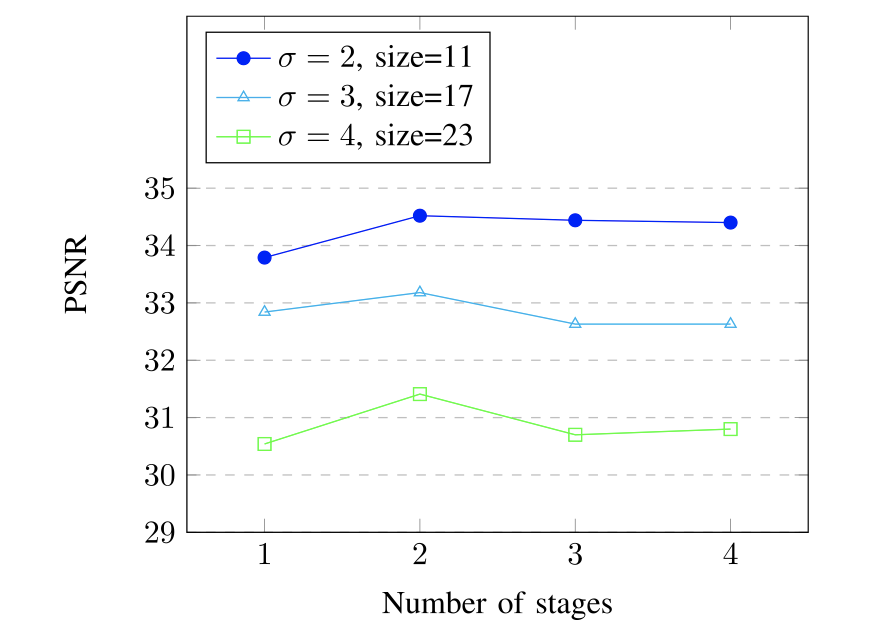
(渐近残差学习模块层级数量分析图)
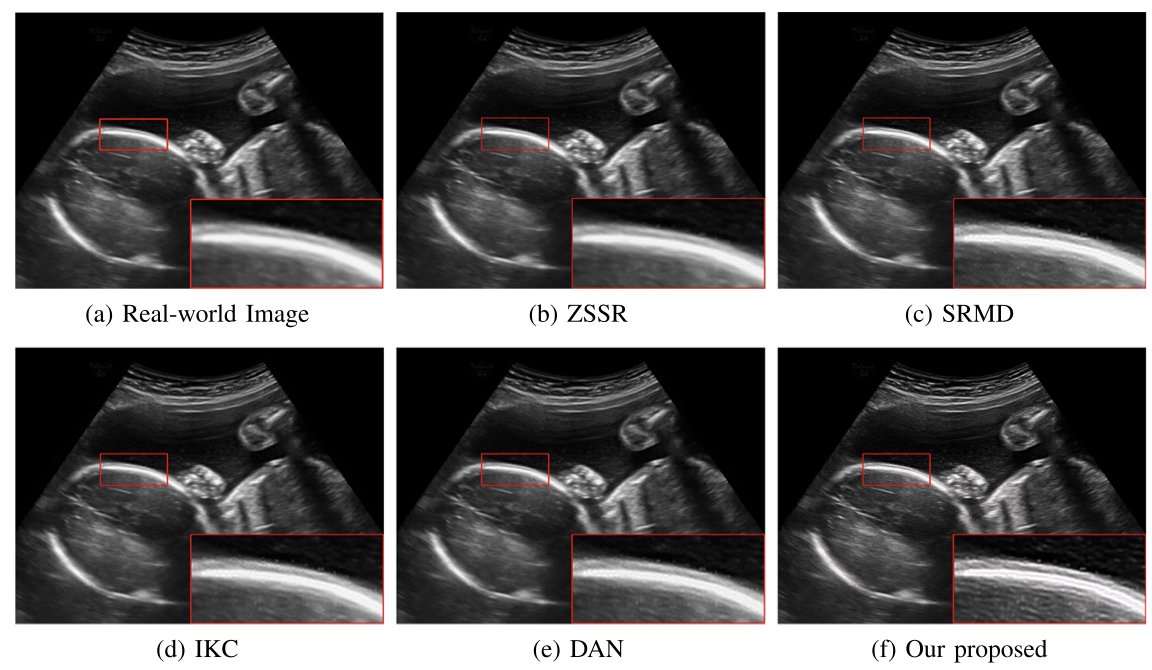
(真实场景超声影像盲超分效果对比图)
行人重识别任务旨在解决跨视角条件下行人图像检索问题,是计算机视觉和生物特征识别领域的一个重要研究方向。由于不同域之间差异的存在,已有行人重识别研究在实际应用中存在跨域性能良的问题。团队在分析现有无监督行人重识别方法的基础上,提出一种利用色彩空间特性来丰富数据多样性的方法,进而借助增广数据之间的语义关联性和多重聚类算法来提升伪标签的置信度。相关研究成果发表在人工智能、计算机视觉领域一区TOP期刊《Pattern Recognition》(IF: 8.0)。我校为论文第一完成单位,工本口子库漫画陈峰博士为第一作者。

(多域联合学习无监督行人重识别)
以上研究工作得到国家自然科学基金、安徽省自然科学基金及安徽省高校协同创新等项目的资助支持。
论文链接:
https://iccv2023.thecvf.com
https://ieeexplore.ieee.org/document/9684683
https://www.sciencedirect.com/science/article/pii/S0031320323000705?via%3Dihub
(撰稿:刘恒 审核:陶陶 吴宣够 韩军书)
")